Introduction
Large Language Model inference systems operate under strict performance constraints, in which latency, throughput, cost, and energy must be balanced across shared infrastructure. As deployment scales across multi-GPU servers and distributed environments, the problem becomes one of optimising resource sharing in LLM inference systems. This reflects broader AI system architecture and infrastructure scaling challenges observed on modern compute platforms.
The underlying issue is structural. Multiple concurrent requests compete for compute, memory, and network bandwidth. Each request progresses through different execution phases, and its behaviour is often unknown at the time of scheduling. As a result, system performance depends on how effectively resources are allocated, pre-empted, and shared across workloads. These challenges reflect system-level design and verification approaches required for complex, heterogeneous systems.
This article draws on recent research discussions and system-level observations, highlighting that improvements in inference performance are primarily achieved through better coordination across the stack rather than through isolated optimisation.
Key learning points
| Key learning point | Link to detailed explanation | External reference link |
| LLM inference performance depends on coordinated compute, memory, and network resource management | The system-level challenge in LLM inference | [1] |
| Prediction-based scheduling improves latency by estimating request characteristics early | Prediction-based scheduling in LLM systems | [1] |
| KV cache management introduces critical memory trade-offs during execution and tool calls | Memory management and KV cache trade-offs | [1] |
| Multi-GPU systems suffer from PCIe contention and unfair bandwidth allocation | Network and PCIe contention in multi-GPU systems | [1] |
| Future systems require unified intra- and inter-host resource coordination | Towards unified resource management | [1] |
The system-level challenge in LLM inference
LLM inference systems must simultaneously optimise:
- Latency, including time to first token and token generation rate
- Throughput under concurrent request load
- GPU memory utilisation, particularly KV cache
- Energy and infrastructure cost
These metrics are interdependent. Improving one often degrades another.
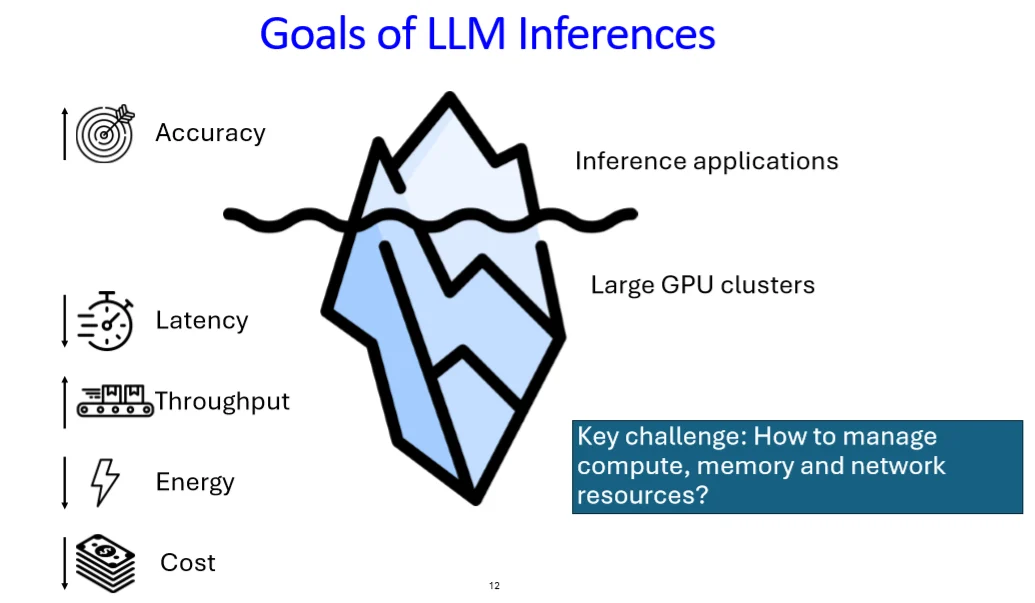
Figure 1: LLM inference system resource interaction [1]
Figure 1 shows that inference requests are not isolated. Each request consumes GPU compute cycles, occupies KV cache memory, and generates communication traffic across interconnects. When multiple requests are active, contention emerges across all three dimensions.
This leads to a central design question: How should resources be shared across requests with unknown and variable behaviour?
Prediction-based scheduling in LLM systems
Traditional scheduling algorithms assume knowledge of job size. In LLM systems, this assumption breaks.
- Output token length is unknown at request arrival
- Requests may pause due to tool calls or external dependencies
- Preemption introduces memory overhead
Conventional approaches include:
- First-come, first-served when the size is unknown
- Shortest Job First when size is known
- Shortest Remaining Processing Time when preemption is allowed
However, these do not map cleanly to LLM workloads.
Prediction-driven approach
Modern systems introduce lightweight predictors that estimate request size using internal model signals. These predictions enable scheduling decisions closer to SRPT behaviour without full knowledge of execution time.
One example is a system that:
- Predicts output token length early in execution
- Enables preemption only when memory overhead is acceptable
- Disables preemption once KV cache grows
This approach improves latency under load while controlling memory growth.
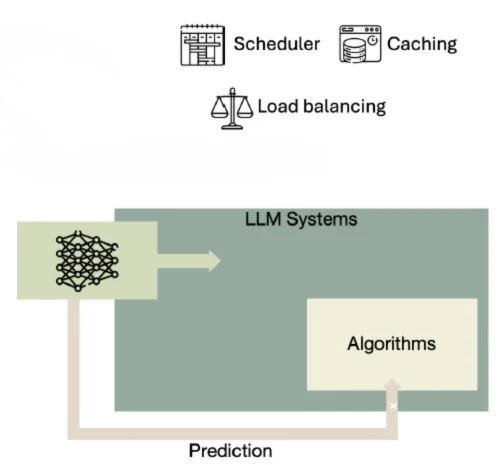
Figure 2: Prediction-based scheduling loop [1]
Figure 2 shows a feedback-driven scheduler where predictions guide request ordering. The key insight is that even imperfect predictions significantly improve scheduling quality when compared to blind ordering. These decisions reflect a broader risk-based verification strategy and decision confidence in complex systems.
Memory management and KV cache trade-offs
Memory is the dominant constraint in LLM inference systems. The KV cache grows with each generated token and remains allocated for the duration of a request.
This introduces a fundamental trade-off:
- Preemption reduces latency but increases memory usage
- Larger KV cache reduces batch size and overall throughput
Tool call complexity
When requests invoke external tools:
- Execution pauses
- KV cache remains allocated
- Memory may be underutilised
At this point, systems must choose between:
- Preserving KV cache in GPU memory
- Discarding it and recomputing later
- Swapping it to CPU or remote memory
Each option has different implications for latency and memory pressure.
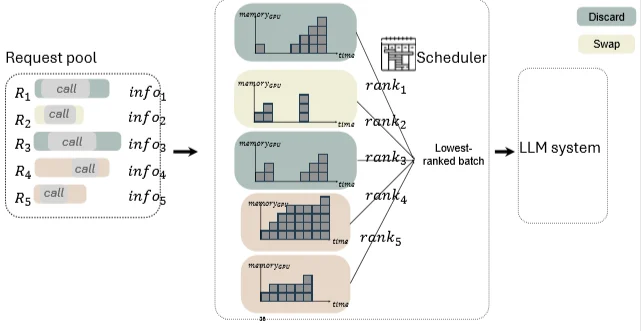
Figure 3: KV cache memory lifecycle during tool calls [1]
The key observation is that memory cost is not static. It depends on both size and duration. Two requests using the same memory footprint may have very different system impact depending on how long the memory is occupied.
Advanced schedulers, therefore, rank requests based on predicted memory over time, rather than token count alone.
Network and PCIe contention in multi-GPU systems
As systems scale, communication becomes a dominant factor.
LLM inference involves:
- GPU-to-GPU communication for parallelism
- KV cache movement between memory tiers
- CPU-GPU transfers
- Remote memory access via RDMA
These interactions create contention across heterogeneous interconnects.
Observed issues
From system-level measurements:
- Multiple GPUs sharing the same CPU PCIe root complex experience degraded latency
- Bandwidth sharing is not uniform due to protocol-level constraints
- PCIe arbitration is transaction-based rather than byte-based
For example:
- RDMA traffic may receive a larger share of bandwidth than expected
- Smaller transactions may be disadvantaged under contention
These behaviours are not visible at the application level but have direct impact on inference latency.
Structural limitation
PCIe hierarchy imposes constraints:
- Devices under the same root complex compete for shared links
- Paths to CPU memory are partitioned
- Load balancing across links is limited
This leads to non-linear scaling behaviour when adding GPUs.
Towards unified resource management
Current systems treat compute, memory, and network scheduling as separate problems. This separation limits optimisation potential.
A more effective approach requires:
- Coordinating scheduling decisions across all resource domains
- Integrating intra-host and inter-host networking awareness
- Using global addressing and routing mechanisms
Two critical limitations today:
- Inter-host networks terminate at the NIC and lack visibility into GPU topology
- Intra-host protocols do not support forwarding across heterogeneous links
As a result, alternative communication paths often remain unused, even when available.
Future systems must address:
- End-to-end routing across GPU, CPU, and network fabrics
- Load balancing across PCIe trees and interconnects
- Unified scheduling policies combining compute, memory, and network awareness
Constraints, trade-offs, and risks
Resource sharing optimisation introduces several constraints:
- Prediction accuracy versus computational overhead
- Preemption benefits versus memory growth
- Throughput optimisation versus latency fairness
- Hardware topology limitations versus scheduling flexibility
Trade-offs must be explicitly defined:
- Prioritising short requests improves average latency but may penalise long workloads
- Aggressive batching improves throughput but increases latency variability
- Memory offloading reduces GPU pressure but introduces transfer overhead
Risks include:
- Over-reliance on inaccurate predictions
- Memory fragmentation under dynamic workloads
- Unpredictable performance under heterogeneous communication patterns
Effective system design requires quantifying these trade-offs rather than assuming optimal behaviour.
Conclusion
Optimising resource sharing in LLM inference systems is fundamentally a system-level problem. Improvements in latency and throughput are achieved not by isolated optimisation, but by coordinated control of compute, memory, and network resources.
Prediction-based scheduling, adaptive memory management, and awareness of hardware topology all contribute to measurable gains. However, the current generation of systems remains limited by fragmented control across resource domains.
Future architectures will need to unify scheduling and routing decisions across the full stack, enabling consistent performance under scale and variability.
References
[1] Minlan Yu, Optimizing Resource Sharing in LLM Inference Systems, Open Compute Project (OCP) presentation, 2026.
Available at: https://www.dropbox.com/scl/fi/5hdzpy10i4nx9a9dyhhbp/ocp26-public.pptx?rlkey=3j705wiwg59ifwaq2w0p77m6u&e=1&st=tgfyw39t&dl=0
Further technical exploration
For readers interested in deeper engineering approaches:

Written by : Mike Bartley
Mike started in software testing in 1988 after completing a PhD in Math, moving to semiconductor Design Verification (DV) in 1994, verifying designs (on Silicon and FPGA) going into commercial and safety-related sectors such as mobile phones, automotive, comms, cloud/data servers, and Artificial Intelligence. Mike built and managed state-of-the-art DV teams inside several companies, specialising in CPU verification.
Mike founded and grew a DV services company to 450+ engineers globally, successfully delivering services and solutions to over 50+ clients.
Mike started Alpinum in April 2016 to deliver a range of start-of-the art industry solutions:
Alpinum AI provides tools and automations using Artificial Intelligence to help companies reduce development costs (by up to 90%!) Alpinum Services provides RTL to GDS VLSI services from nearshore and offshore centres in Vietnam, India, Egypt, Eastern Europe, Mexico and Costa Rica. Alpinum Consulting also provides strategic board level consultancy services, helping companies to grow. Alpinum training department provides self-paced, fully online training in System Verilog, UVM Introduction and Advanced, Formal Verification, DV methodologies for SV, UVM, VHDL and OSVVM and CPU/RISC-V. Alpinum Events organises a number of free-to-attend industry events
You can contact Mike (mike@alpinumconsulting.com or +44 7796 307958) or book a meeting with Mike using Calendly (https://calendly.com/mike-alpinum-consulting).
Stay Informed and Stay Ahead
Latest Articles, Guides and News
Explore related insights from Alpinum that dive deeper into design verification challenges, practical solutions, and expert perspectives from across the global engineering landscape.