
Introduction: Why scale now matters
Datacentre systems-on-chip (SoC) have evolved to a point where many long-standing verification assumptions no longer hold in practice. Modern designs integrate manycore processors, deep cache hierarchies, high-bandwidth memory interfaces, accelerators, and increasingly complex I/O fabrics. These components are exercised under software stacks that, in real deployments, more closely resemble production cloud environments than controlled synthetic benchmarks.
For architecture and verification teams, the emphasis has shifted gradually over recent design cycles. Functional correctness remains a prerequisite, but experience shows that it does not, on its own, provide sufficient confidence in delivered systems. Performance, scalability, and system behaviour must also remain predictable once realistic workloads interact with hardware, firmware, operating systems, and runtime libraries.
Software RTL simulation continues to provide essential debug visibility and remains central to early-stage verification. In practice, however, it cannot execute full-system workloads at a scale that reflects datacentre operation. FPGA-accelerated simulation addresses this limitation by offering orders-of-magnitude higher execution throughput, enabling the execution of operating systems and real applications in cycle-accurate mode. Extending these platforms to warehouse-scale systems introduces practical constraints, particularly around compilation time, resource utilisation, and iteration latency.
Recent academic and open-source work highlights how these constraints can be addressed through hardware–software co-design, partial reconfiguration, and workload-representative benchmarking [1].
Why conventional simulation and benchmarks fall short
Software simulation does not scale to system realism
Cycle-accurate software simulators provide excellent observability, but their execution rates collapse as core counts and system complexity increase. Running a full Linux stack or datacentre application can take days or weeks of simulated time, making them unsuitable for performance validation or large-scale design exploration.
As a result, many architectural decisions are validated using reduced configurations, synthetic tests, or extrapolated models. These shortcuts introduce risk, particularly when system behaviour is dominated by memory traffic, I/O interactions, or operating system effects rather than core microarchitecture alone.
Traditional benchmarks misrepresent datacentre behaviour
Industry benchmarks such as SPEC CPU were not designed to reflect warehouse-scale workloads. They tend to be single-process, compute-centric, and weakly representative of microservice-based software stacks.
Empirical studies of hyperscale systems show that such benchmarks systematically mispredict performance for modern servers, particularly in areas dominated by memory movement, RPC overhead, synchronisation, and operating system activity [2]. These effects, often described as datacentre tax, dominate real workloads but remain invisible to conventional benchmarks.
This mismatch undermines confidence in early architectural trade-offs and makes it challenging to correlate pre-silicon results with post-silicon behaviour.
FPGA-accelerated simulation as a system-level tool
FPGA-accelerated simulation bridges the gap between slow software simulators and abstract performance models. By mapping RTL designs onto FPGA fabric, it becomes possible to execute cycle-accurate hardware models at megahertz-class speeds while running unmodified operating systems and applications.
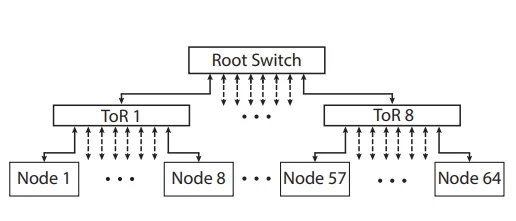
Figure 1: Scale-out target topology in FPGA-accelerated simulation [3].
However, two fundamental limitations emerge when these platforms are scaled to datacentre-class systems:
- FPGA compilation time – Iterative builds can require many hours, severely constraining design-space exploration and architectural iteration.
- FPGA resource constraints – Warehouse-scale SoCs place significant pressure on logic capacity, routing resources, and timing closure, even on large datacentre-class FPGAs.
Addressing these limitations requires changes not only to individual tools, but to the structure and assumptions of the simulation flows themselves.
Reducing iteration latency through partial reconfiguration
One of the most significant bottlenecks in FPGA-accelerated simulation is rebuild time. In many architectural studies, only a small subset of the design changes between iterations, yet the entire FPGA image must be rebuilt from scratch.
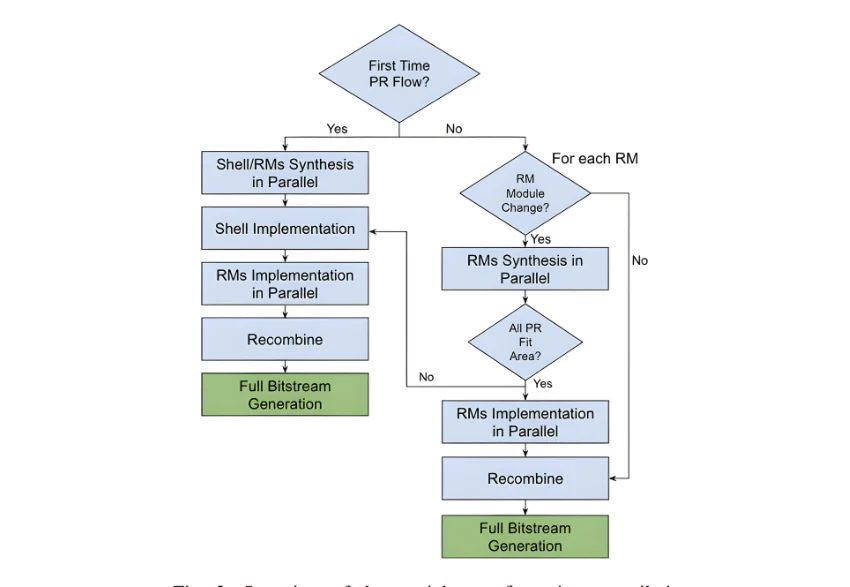
Figure 2: Partial reconfiguration flow for FPGA-accelerated simulation [1]
By constraining change to well-defined reconfigurable regions, partial reconfiguration decouples frequently modified logic from the surrounding infrastructure and enables reuse of placement and routing results across iterations. The partial reconfiguration flow preserves cycle accuracy at the system level while substantially reducing turnaround time.
Recent work applying partial reconfiguration in FPGA-accelerated simulation environments demonstrates order-of-magnitude reductions in iterative compile time with minimal manual intervention [1]. For verification and architecture teams, this translates directly into improved productivity and broader design-space exploration under realistic system workloads.
Multithreading and resource trade-offs in FPGA simulation
FPGA capacity remains finite, even in datacentre deployments. As system complexity increases, techniques such as time-multiplexed simulation become necessary to allow repeated hardware structures to share FPGA resources while preserving functional correctness.
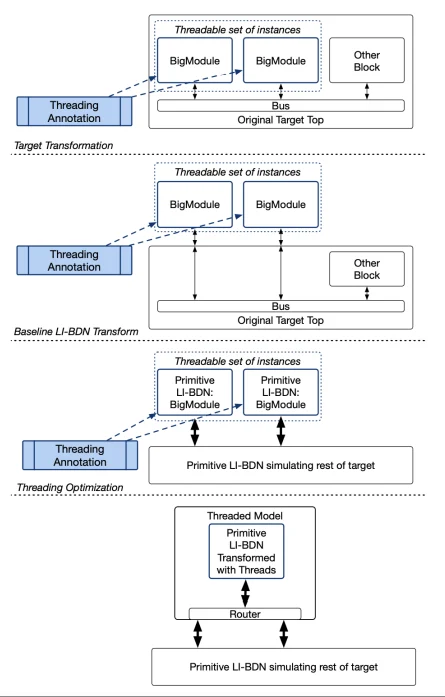
Figure 3: Multithreaded FPGA simulation using LI-BDN and FAME-5 [1].
These trade-offs are not purely performance-driven. While multithreading preserves functional correctness and system-level interactions, it increases the FPGA cycle-to-model cycle ratio, thereby reducing the absolute simulation speed. As a result, this approach must be applied selectively, particularly where timing fidelity or fine-grained performance analysis is required.
Recent extensions relax earlier constraints by allowing heterogeneity among threadable instances and enabling parallel multithreaded execution, exposing a broader design space spanning area, throughput, and fidelity [1]. These techniques are most effective when aligned with simulation semantics and architectural intent, rather than applied as generic CAD optimisations.
Workload realism: beyond synthetic performance tests
Scaling simulation infrastructure alone is insufficient if the workloads being exercised are not representative. Datacentre systems are shaped as much by software architecture and system interactions as by individual hardware components.
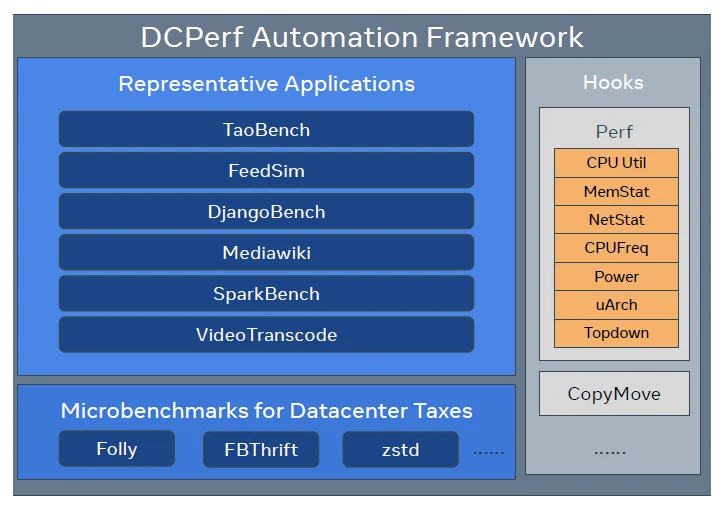
Figure 4: DCPerf automation framework for datacentre workloads [2].
Open-source benchmark suites such as DCPerf were developed to address this gap by providing workload models that reflect real datacentre services rather than abstract kernels [2]. When these benchmarks are executed within FPGA-accelerated simulation environments, they enable performance verification under conditions that more closely resemble production behaviour. Executing these benchmarks within FPGA-accelerated simulation environments exposes effects such as kernel bottlenecks, cache-coherence stress, and interactions between accelerators and system software that are difficult to observe with conventional benchmarking approaches.
Constraints, trade-offs, and verification risk
While these advances are promising, they introduce their own constraints that must be understood. Partial reconfiguration requires disciplined partitioning. Changes that exceed predefined resource boundaries can force complete rebuilds, reducing the expected benefit. Similarly, multithreaded simulation trades timing fidelity for capacity and must be applied selectively depending on verification goals.
There is also a fundamental trade-off between simulation speed and cycle-exactness. Fast modes that inject latency or modify interfaces may be acceptable for architectural exploration but unsuitable for sign-off-level validation.
The value lies not in eliminating trade-offs, but in making them explicit and controllable.
Why this matters for datacentre silicon programmes
As datacentre systems continue to evolve, verification confidence increasingly depends on system-level evidence rather than isolated metrics. Decisions around core counts, cache hierarchies, memory subsystems, and accelerators cannot be validated in isolation.
FPGA-accelerated simulation, when combined with realistic workloads and scalable iteration flows, enables earlier visibility into integration risk, performance bottlenecks, and software interactions. This earlier system-level visibility reduces late-stage surprises and improves alignment between architectural intent and delivered silicon.
Continue Exploring
If you would like to explore more work in this area, see the related articles in the FPGA Front Runner section on the Alpinum website:
https://alpinumconsulting.com/resources/blog/fpga-front-runner/
For discussion, collaboration, or technical engagement, contact Alpinum Consulting here:
https://alpinumconsulting.com/contact-us/
References
[1] J. Kim et al., Scaling FPGA-Accelerated Simulation for Datacenter Workloads, UC Berkeley, 2025.
Available at:
https://people.eecs.berkeley.edu/~kubitron/courses/cs262a-F25/projects/reports/project1015_paper_49711590065163526859.pdf
[2] W. Su et al., DCPerf: An Open-Source Performance Benchmark Suite for Datacenter Workloads, ISCA, 2025.
Available at:
https://dl.acm.org/doi/epdf/10.1145/3695053.3731411
[3] A. Waterman et al., FireSim: FPGA-Accelerated Cycle-Exact Scale-Out System Simulation, ISCA, 2018.
Related extended work and tooling context available at:
https://sagark.org/assets/pubs/firesim-isca2018.pdf

Written by : Mike Bartley
Mike started in software testing in 1988 after completing a PhD in Math, moving to semiconductor Design Verification (DV) in 1994, verifying designs (on Silicon and FPGA) going into commercial and safety-related sectors such as mobile phones, automotive, comms, cloud/data servers, and Artificial Intelligence. Mike built and managed state-of-the-art DV teams inside several companies, specialising in CPU verification.
Mike founded and grew a DV services company to 450+ engineers globally, successfully delivering services and solutions to over 50+ clients.
Mike started Alpinum in April 2025 to deliver a range of start-of-the art industry solutions:
Alpinum AI provides tools and automations using Artificial Intelligence to help companies reduce development costs (by up to 90%!) Alpinum Services provides RTL to GDS VLSI services from nearshore and offshore centres in Vietnam, India, Egypt, Eastern Europe, Mexico and Costa Rica. Alpinum Consulting also provides strategic board level consultancy services, helping companies to grow. Alpinum training department provides self-paced, fully online training in System Verilog, UVM Introduction and Advanced, Formal Verification, DV methodologies for SV, UVM, VHDL and OSVVM and CPU/RISC-V. Alpinum Events organises a number of free-to-attend industry events
You can contact Mike (mike@alpinumconsulting.com or +44 7796 307958) or book a meeting with Mike using Calendly (https://calendly.com/mike-alpinumconsulting).
Stay Informed and Stay Ahead
Latest Articles, Guides and News
Explore related insights from Alpinum that dive deeper into design verification challenges, practical solutions, and expert perspectives from across the global engineering landscape.

